Einleitung – Was ist Microsoft Fabric?
Die Erweiterung von Power BI auf Fabric wurde von Microsoft im Mai 2023 angekündigt, gefolgt von der Markteinführung im November 2023. Mit einem Upgrade auf Fabric wird der Power BI Service (app.PowerBI.com) signifikant erweitert und mit vielen zusätzlichen Tools zur umfassenden Analyticsplattform.
Die wichtigsten zusätzlichen Tools sind die folgenden:
- Lakehouses und Warehouses (siehe unten)
- Pipelines zur Abbildung von ETL-Ketten
- Erweiterte Version der beliebten Dataflows (Low-Code Datentransformation mit Power Query)
- Nutzung von Spark Notebooks für die Ausführung von Python oder R Code
- Erstellung und Operationalisierung von Machine Learning Modellen
- Integration von Streamingdaten
Diese zusätzlichen Funktionen sind natürlich voll integriert mit Power BI. So kann ich z.B. Daten per Pipeline in ein Lakehouse laden, diese mit Python in einem Notebook transformieren und die finalen Daten dann in einem Power BI Bericht visualisieren.
Anzumerken ist, dass viele dieser Tools bereits schon länger existieren, jedoch früher nur in der Azure-Umgebung (Synapse, Data Factory etc.).
Lizensierung und Kosten von Fabric
Damit Fabric verwendet werden kann muss eine entsprechende Kapazität über das Azure Portal lizensiert werden. Abgerechnet werden kann dann entweder Nutzungsbasiert (pro Zeit) oder per monatlicher Reservation. Eine Kapazität kann flexibel hoch- oder runterskaliert werden. Die kleinste Kapazität “F2” mit bspw. 15 Power BI Usern kostet CHF 325.- pro Monat (vs. 150.- bei nur Power BI Pro). Diese kleinste Kapazität ist bereits schon ausreichend für viele Use-Cases im KMU-Umfeld. Weitere Informationen zum Pricing finden sich hier.
Wurde eine Kapazität erstellt, muss ein Power BI Workspace dieser zugeordnet werden, sodass die erweiterten Funktionen verfügbar werden.
Das Fabric Lakehouse: Komponenten und Anwendung für Analytics Use-Cases
Das oben bereits genannte Lakehouse ist der Kern von Fabric. Ein Lakehouse integriert die Vorteile eines (File-basierten) Data Lakes mit denen eines klassischen (SQL-basierten) Data Warehouses.
Datentabellen in einem Lakehouse werden mit sogenannten Delta-Tabellen abgebildet, welche auf Parquet-Files basieren. Die technischen Details sind hier nicht relevant, jedoch ist wichtig festzustellen, dass die Delta-Table Technologie eine sehr schnelle Datenverarbeitung- und Abfrage erlaubt (z.B. in Dashboards).
Die folgende Darstellung zeigt die Komponenten sowie die Anwendung eines Lakehouses als Teil der Datenarchitektur:
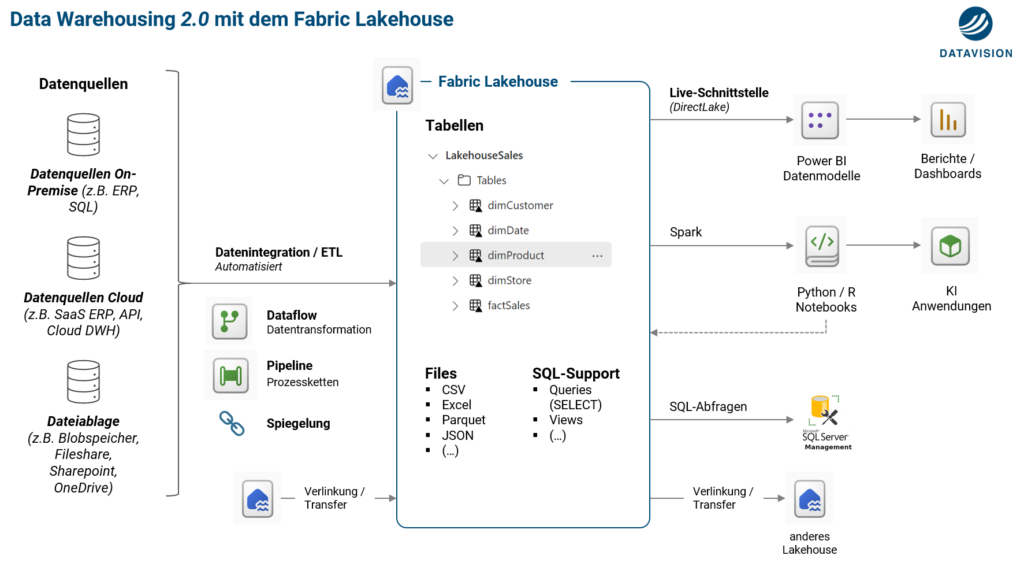
In der Folge werden die gezeigten Komponenten und deren Anwendung kurz erklärt.
Komponenten eines Lakehouses
Ein Lakehouse hat die folgenden Komponenten:
- Fileablage : Hierbei handelt es sich um die Data Lake Komponente des Lakehouses. Files unterschiedlicher Formate können in Ordnerstrukturen im Lakehouse gespeichert werden. Diese Files können automatisiert in das Lakehouse synchronisiert werden, bei Bedarf mit vorheriger Datentransformation
- Tabellen : Datentabellen auf Basis der Delta-Table Technologie. Diese können entweder per ETL erstellt und befüllt werden, oder direkt aus dem Data Lake (Files) abgeleitet werden
- SQL-Support : Über einen sogenannten SQL-Endpoint können mit SQL-Code Abfragen (Queries) gemacht werden. Solche Abfragen können auch zur Wiederverwendung als View gespeichert werden. Für eine volle T-SQL Unterstützung kann neben dem Lakehouse mit einem Warehouse gearbeitet werden. Beide Architekturen können per Knopfdruck miteinander verlinkt werden (Tabellen werden gespiegelt)
- Semantisches Modell : Ein jedes Lakehouse hat ein oder mehrere semantische Modelle (Power BI Datenmodell) basierend auf welchen mit Power BI Berichte erstellt werden können. Ein solcher Bericht nutzt dann die DirectLake Schnittstelle auf das Lakehouse, was eine sehr hohe Abfrageperformance erlaubt
Anwendung des Lakehouses für Analytics Use-Cases
Kurz umschrieben ist das Lakehouse der zentrale Dreh- und Angelpunkt wo alle unsere Daten aus den unterschiedlichsten Quellen zusammenkommen und integriert werden.
Wir verwenden Pipelines und Dataflows, um die Datenquellen ohne Code anzubinden, die Rohdaten in nutzbare Tabellen zu transformieren und in das Lakehouse zu schreiben. Diese Tabellen werden dann regelmässig und automatisiert aktualisiert. Abhängigkeiten in der Aktualisierungskette können dabei problemlos abgebildet werden. Weiterhin können auch ganze Clouddatenbanken gespiegelt werden (z.B. Snowflake).
Unser Data Scientist nutzt die Daten in einem Spark Notebook und erstellt mit R Code ein Machine Learning Modell (Algorithmus), welches eine Umsatzprognose ableitet. Diese Umsatzprognose stellen wir in Power BI visuell dar.
Für eine Historisierung bestimmter Datenstände analog einer klassischen DWH-Lösung können wir das Warehouse nutzen, welches uns alle üblichen T-SQL Funktionen bietet. Das Warehouse können wir mit dem Lakehouse problemlos verlinken.
Die Tabellen im Lakehouse bilden dann die Grundlage für das Erstellen von Visualisierungen, Berechnungen und Berichten mit Power BI. Die Berichte sind extrem performant, trotz einer sehr grossen Datenmenge, und müssen nicht aktualisiert werden, dank der DirectLake Technologie.
Andere Teams in der Firma können ihre eigenen Power BI Berichte mit Tabellen aus dem Lakehouse ergänzen, was Doppelspurigkeiten vermindert und die Data Governance sowie Standardisierung vorantreibt.
Beispiel
Folgendes Schaubild zeigt, wie so ein Lakehouse für eine Gastrogruppe aussehen könnte. Wie man sieht, integrieren wir die unterschiedlichsten Datenquellen an einem Ort. Sogar das Ergebnis unserer Machine Learning Applikation ist enthalten, die Umsatzprognose:

Für wen kommt ein Upgrade auf Fabric in Frage?
Für ein Upgrade auf Fabric gibt es mehrere Gründe, welche im Einzelfall unterschiedlich relevant sind. Folgendes kann generell gesagt werden:
- Die Datenaktualisierungskette ist mehrstufig und hat mehrere Abhängigkeiten, was eine Orchestrierung bzw. Steuerung mehrere Prozesse erfordert mithilfe von Pipelines
- Die Datenmenge ist sehr gross oder wird immer grösser, was zu langen Aktualisierungszeiten führt. Dies kann mit Delta-Loads sowie der Nutzung des DirectLake-Mechanismus behoben werden
- Es gibt Machine Learning Use-Cases mit der Verwendung von Python oder R, welche die gleichen Datenbestände benötigen, wie das sonstige BI. Diese Anwendungen sollen mit dem BI tief integriert sein
- Es soll generell eine ganzheitliche Analyticsplattform implementiert werden, welche die Bedürfnisse aller befriedigt. Der Controller arbeitet Low-Code mit Power Query, die Data Scientistin arbeitet am liebsten mit Python, die Datenbankadministratorin kann am besten SQL etc.
- Eine verbesserte Standardisierung und Wiederverwendung von Datenprodukten (z.B. Tabellen) soll gefördert werden
- Für die bestehende DWH-Lösung soll ein Refactoring in die Cloud gemacht werden
- Es sollen Streamingdaten in das BI integriert werden
- Das bestehende BI Setup mit Power BI soll generell erweitert werden im Zuge einer kontinuierlichen Weiterentwicklung zum Datengetriebenen Unternehmen
Natürlich ist diese Liste nicht abschliessend und es gibt einige weitere potenzielle Beweggründe.
Für weiterführende Informationen oder ein unverbindliches Gespräch zur Ersteinschätzung stehen wir gerne zur Verfügung!